
Today, accurately estimating the value of an ad impression requires acquiring and structuring 100-1,000 times more data compared to a decade ago. That’s because ten years ago the amount of data used to predict an impression value was limited to traffic from the publisher’s websites running the ad campaign, or from the first-generation of publisher networks.
Since then, real-time bidding (RTB) networks have transformed audience targeting by connecting publishers and advertisers all around the world in a programmatic RTB auction. Now, thousands of advertisers bid for impressions from dozens of different publishers in real time and performance marketers have more data than ever before to make reliable estimates of an ad impression’s value. Even “lost” opportunities help advertisers understand the market and estimate the cost of an impression better.

So, how much data are we talking about?
In the US alone there are more than 250 million active Internet users, and many of them use multiple Internet devices. If we consider the world as a whole, the number of active Internet users is close to 3-4 billion. Certainly, not all users are eligible for all marketing campaigns.
Regardless, for performance marketing to be effective, advertisers need the ability to discover and apply business-critical insights from petabyte datasets in real time to determine which impressions are most likely to respond positively to an ad. And it is the data management platform (DMP) that is responsible for collecting and storing the multiple anonymized user attributes (like country and language) from the billions of Internet users that are needed to differentiate user patterns.
This data is usually provided by an ad network, but there are also dedicated external systems that supply additional information associated with a user, for example purchaser profiles from online web stores. Another way DMPs collect (a lot of) data is from the marketing campaigns themselves. For the last several years, the amount of data LifeStreet processed and stored tripled every 18-24 months, reaching 300 billion records per day, greatly exceeding the maximum volume of data processed in previous years.
Why is data processing so hard?
So let’s break it down: 300 billion records per day means approximately 5 million records per second. This is a lot of data. Every bid request generates a record with hundreds of different attributes provided by the RTB network and DMP system. The record size may be several kilobytes. Simple math gives us gigabytes per second and tens of terabytes of data every day that need to be stored in a database. To put it into perspective, a typical laptop has less than one terabyte of disk space and could only store less than an hour’s worth of bid request data.
The challenge is not only to store this amount of data quickly and reliably, but also to make it available for further analysis by humans and machine learning algorithms. Data is useless if it is not actionable. Performance marketing requires us to look back on weeks or even months of data in order to find user patterns, build performance profiles, make predictions, and estimate impression value. That means several hundred terabytes or petabytes of data need to be readily available for market analysts, dashboards, and machine learning algorithms.
Think of a typical marketing data report. From the giant volume of data being stored, only a fraction is needed for a particular report because each report only requires a unique subset of the data attributes available. But there could be many reports with different ‘views’ of the data, and different ways to navigate between those views. This is a common analytics function, and database systems learn how to do this effectively with a technology called a column store.

Row Store vs. Columnar Store
In traditional databases, data is stored by rows, and when data is queried full rows need to be accessed. This works for small datasets but becomes prohibitively expensive and slow for reports with billions of rows. Conversely, columnar databases store data by columns that make it possible to retrieve only those columns that are required for the particular report. This reporting architecture enables significantly better data compression, reducing by 10,000-1,000,000 times the amount of data that needs to be processed by a single report.

Columnar databases first appeared in 1998 but were infrequently used during the next decade–the era of Big Data hadn’t yet arrived. In 2010, when LifeStreet first started using commercial columnar databases, we were one of the first ad tech companies using this technology. But prohibitive licensing fees and real-time performance shortcomings limited our ability to execute real-time analytics at scale. That is, until we discovered ClickHouse in 2016.
Why ClickHouse is LifeStreet’s data warehouse solution
ClickHouse was the first database management system that met all of LifeStreet’s requirements:
- Real-time data ingestion from hundreds of ad servers
- Ad-hoc rapid reporting that outperformed other technologies
- Ability to quickly scale a cluster from several TB to 5PB of data
- Cost effective open-source platform, you only pay for the hardware
- Easy to maintain using only one database administrator to support multi-region, highly available clusters

Current ClickHouse database size on one replica.
ClickHouse was originally developed by Yandex, often considered to be the Russian Google. Yandex developed ClickHouse to power an analytic application for its own massive ad network and decided to make it an open source platform, following the trend set by Yahoo, Google, Facebook and other Internet giants who were releasing (and continue to release) open source products.
Probably the most important feature of ClickHouse is its querying speed compared to other databases. ClickHouse can complete a query on tables with billions of records in subseconds, which is a tremendous advantage to the business itself. The faster queries run, the more data insights that can be found. With previous database solutions, LifeStreet’s marketing analysts often suffered from, “not-worth-trying-disease.” If something took more than 15 minutes to query–forget it. With ClickHouse, ad hoc data exploration became easy and possible.
At LifeStreet, we use ClickHouse in a variety of ways and because we are able to use just one database technology for multiple tasks, we’ve reduced infrastructure and team overhead. But we primarily use it for storing several trillions of rows of RTB data in a huge geo-distributed cluster. This cluster serves millions of queries every day and powers reports, dashboards, machine learning algorithms, and ad-hoc exploratory analysis. Because ClickHouse powers LifeStreet’s reporting, we have been able to build a reporting platform recognized by our users as one of the best in market.
ClickHouse is also used for storing real-time campaign budgets, DMP data, and raw logs; and with Apple’s iOS 14 privacy changes, the value, accessibility, and use of data increases exponentially.
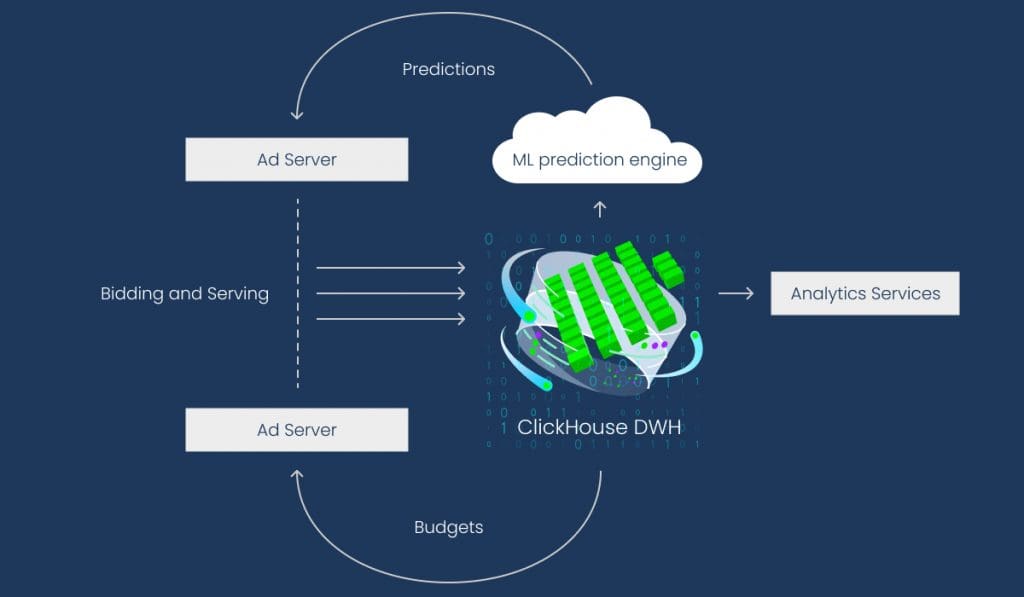
How LifeStreet uses ClickHouse DWH (Data Warehouse).
Invest in innovation
At the time we started using ClickHouse, it was a brand new technology and considered by some to be a risky decision. But we carefully assessed the risk by running a lot of experiments and tests before making a decision to invest in the columnar database system. Over the years, ClickHouse has evolved, grown, and matured to become the database management system of choice among ad tech, telecom, financial and other industries where massive amounts of machine-generated data requires fast analysis.
We were an early adopter of ClickHouse and by investing in an innovative data warehouse, we were able to build a robust reporting system, enabling our business analysts to generate and learn from the detailed reporting required to optimize performance.
About the author: Alexander Zaitsev joined LifeStreet in 2005 as the Director of Engineering and was responsible for the company’s analytical infrastructure and overseeing the development of big data technologies. In 2017, he launched his own company, Altinity and continues working with LifeStreet as its data engineering consultant.